Fitness-Tracking-Apps wie Runkeeper sammeln eine Menge interessanter Daten. Mit ein paar Python-Kenntnissen können die Läufe noch detaillierter ausgewertet werden als in der App. Im ersten Teil dieser Serie werde ich einen einzelnen GPS-Track (GPX-Datei) mit Python untersuchen, dabei verwende ich Geopandas und Folium. Manche Ideen stammen von diesem Blogbeitrag, aber ich habe einen eleganteren Weg gefunden, ohne durch den GeoDataFrame zu iterieren. Außerdem füge ich nützliche Tooltips zur Karte hinzu. Im zweiten Teil ändere ich den Code, um einen GeoDataFrame mit allen meinen GPS-Tracks zu erhalten. Dieser eignet sich hervorragend zum Plotten und Analysieren der Läufe. Teil 2 enthält ein Jupyter-Notebook, das Sie mit Ihren eigenen GPS-Tracks verwenden können.
Download the GPS Tracks
Um die mit Runkeeper aufgenommenen GPS-Tracks herunterzuladen, muss man sich auf https://runkeeper.com/ einloggen. Dann auf das Zahnrad-Icon klicken, „Account Settings“ wählen und dann „Export Data“. Man bekommt ein ZIP, das die GPS-Tracks als einzelne GPX-Dateien enthält. (Vor ein paar Monaten musste ich 2 Tage warten, bis der endgültige Download-Link erschienen ist. Letzte Woche funktionierte es sofort.)
GPX-Dateien in Geopandas öffnen
Geopandas kann GPX-Dateien öffnen und parsen (dabei wird GDAL verwendet). Um einen GeoDataFrame mit allen Punkten entlang des Tracks zu bekommen:
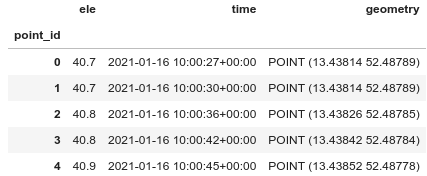
import pandas as pd import geopandas as gpd import numpy as np from shapely.geometry import LineString file = "gpx/2021-01-16-110027.gpx" gdf = gpd.read_file(file, layer='track_points') gdf.head()

Zu Höhenangaben von Runkeeper siehe Mit Python einem GPS-Track die Höhe hinzufügen. Wir sehen viele Spalten mit „None“-Werten, die wir löschen können. Beachten Sie die Spalten „track_fid“, „track_seg_id“ und „track_seg_point_id“: Sie werden von GDAL verwendet, um verschiedene Tracks, Segmente und Trackpoints zu identifizieren, die sich in einer einzelnen GPX-Datei befinden können. Runkeeper beginnt nach einer Pause ein neues Track-Segment, daher können wir nicht einfach track_seg_point_id als Index verwenden. Ich werde den von Geopandas erstellten Index als „point_id“ benennen und die anderen Spalten löschen. Das Ergebnis enthält die Pausen. Ich wandle die Zeit zu Datetime.
# Better use the geodataframe index as point_id gdf.index.names = ['point_id'] # And turn time to Datetime gdf['time'] = pd.to_datetime(gdf['time']) # Drop useless columns gdf.dropna(axis=1, inplace=True) gdf.drop(columns=['track_fid', 'track_seg_id', 'track_seg_point_id'], inplace=True) gdf.head()
Informationen aus dem GPS-Track extrahieren
Wie lange hat der Lauf gedauert (einschließlich Pausen)?
total_time = gdf.iloc[-1]['time'] - gdf.iloc[0]['time'] total_time
Timedelta(‚0 days 00:42:26‘)
Jetzt berechnen wir die Entfernung von Punkt zu Punkt. Zunächst müssen wir die Geometrie auf UTM umstellen, um Koordinaten in Metern statt in Grad zu erhalten. Mit neueren Versionen von geopandas und pyproj ist es einfach, die beste UTM-Zone zu ermitteln:
gdf = gdf.to_crs(gdf.estimate_utm_crs())
Jetzt erstelle ich einen zweiten GeoDataFrame, dessen Index um -1 verschoben ist. Mit diesem Trick ist es einfach, die Entfernung von einem Punkt zum nächsten zu berechnen.
shifted_gdf = gdf.shift(-1) gdf['time_delta'] = shifted_gdf['time'] - gdf['time'] gdf['dist_delta'] = gdf.distance(shifted_gdf)
Hinweis: Die letzte Zeile von shifted_gdf besteht aus NaN-Werten. Daher erhalten wir für die letzte Zeile von gdf auch NaN als distance (vom letzten Trackpoint gibt es keinen Abstand zum nächsten Trackpoint).
Nun können wir die Geschwindigkeit in verschiedenen Formaten berechnen:
# speed in various formats gdf['m_per_s'] = gdf['dist_delta'] / gdf.time_delta.dt.seconds gdf['km_per_h'] = gdf['m_per_s'] * 3.6 gdf['min_per_km'] = 60 / (gdf['km_per_h'])
Die zurückgelegte Strecke (in Metern) und die verstrichene Zeit:
gdf['distance'] = gdf['dist_delta'].cumsum() gdf['time_passed'] = gdf['time_delta'].cumsum()
Weitere nützliche Spalten:
# Minutes instead datetime might be useful gdf['minutes'] = gdf['time_passed'].dt.seconds / 60 # Splits (in km) might be usefull for grouping gdf['splits'] = gdf['distance'] // 1000 # ascent is elevation delta, but only positive values gdf['ele_delta'] = shifted_gdf['ele'] - gdf['ele'] gdf['ascent'] = gdf['ele_delta'] gdf.loc[gdf.ascent < 0, ['ascent']] = 0 # Slope in % # (since ele_delta is not really comparable) gdf['slope'] = 100 * gdf['ele_delta'] / gdf['dist_delta'] # Ele normalized: Startpoint as 0 gdf['ele_normalized'] = gdf['ele'] - gdf.loc[0]['ele'] # slope and min_per_km can be infinite if 0 km/h # Replace inf with nan for better plotting gdf.replace(np.inf, np.nan, inplace=True) gdf.replace(-np.inf, np.nan, inplace=True) # Note the NaNs in the last line gdf.tail()

Einfache Statistik:
gdf.describe()

Der (gesamte) Aufstieg in Höhenmetern:
gdf['ascent'].sum()
Wir können die Geometrie wieder zu WGS84 konvertieren. Dies ist besonders dann sinnvoll, wenn wir Tracks aus verschiedenen Regionen vergleichen wollen (Teil 2).
gdf = gdf.to_crs(epsg = 4326) shifted_gdf = shifted_gdf.to_crs(epsg = 4326)
Jetzt sind Ihre Visualisierungsfähigkeiten gefragt. Z.B. ein einfaches Profil:
sns.relplot(x="distance", y="ele", data=gdf, kind="line") plt.ylim(0, 50)
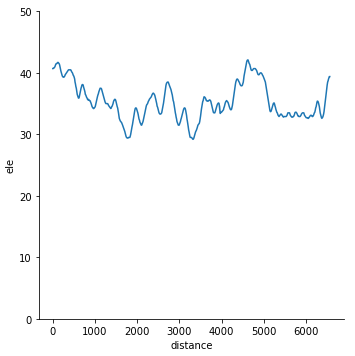
Anmerkung: Ich habe für die y-Achse Grenzen gesetzt, da Berlin ziemlich flach ist und ein geringfügiges Auf und Ab stark übertrieben wäre.
Die Punkte mit Linien verbinden
Wir wollen keine Punkte auf der Karte darstellen, sondern die Linien, die diese Punkte verbinden. Ich erstelle einen weiteren GeoDataFrame mit Linien anstelle von Punkten als Geometrie. Beachten Sie, dass dadurch Informationen wie Zeit und Höhe des letzten Punktes wegfallen. Die Lambda-Funktion verwendet LineString (aus dem Modul shapely), um eine Verbindungslinie zu erstellen. Dann verwenden wir die Linie als neue Geometrie des GeoDataFrame.
lines = gdf.iloc[:-1].copy() # Drop the last row
lines['next_point'] = shifted_gdf['geometry']
lines['line_segment'] = lines.apply(lambda row: LineString([row['geometry'], row['next_point']]), axis=1)
lines.set_geometry('line_segment', inplace=True, drop=True)
lines.drop(columns='next_point', inplace=True)
lines.index.names = ['segment_id']
Wie unterscheiden sich die Splits?
Unsere Spalte "splits" (Abschnitte von 1 km Länge) ist praktisch, um Geschwindigkeit, Steigung usw. entlang der Strecke zu vergleichen. Bin ich am Ende müde geworden? Der folgende Code erstellt eine Tabelle mit vielen interessanten Details für jeden Split, z. B. Mittelwert, Median und Standardabweichung der Geschwindigkeit, Steigung und die für den Split benötigte Zeit.
lines.groupby('splits').aggregate(
{'km_per_h': ['mean', 'median', 'max', 'std'],
'min_per_km': ['mean', 'median', 'max', 'std'],
'ascent': 'sum',
'time_delta' : 'sum' })
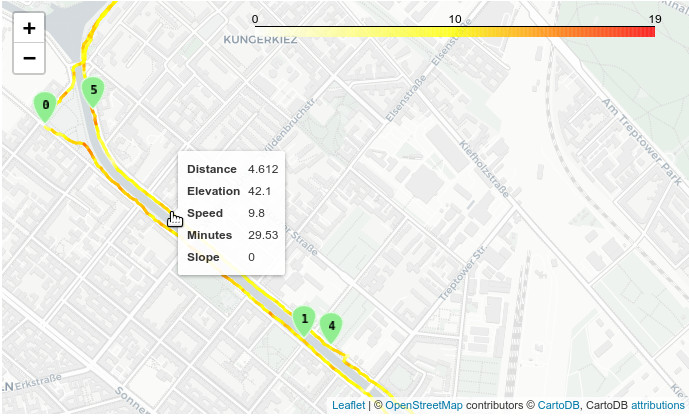
Karte mit Folium
Mit Folium können wir eine interaktive Karte unseres Tracks zeichnen, einschließlich einem praktischen Tooltip mit Informationen zu jedem Linienabschnitt (siehe Screenshot am Anfang dieses Beitrags).
import folium import branca.colormap as cm from folium import plugins # The approx. center of our map location = lines.dissolve().convex_hull.centroid
Ich möchte Markierungen für jeden Kilometer einzeichnen. Wir können den ersten Punkt eines jeden Splits verwenden.
splitpoints = gdf.groupby('splits').first()
Folium mag keine Zeitstempel, diese Spalten müssen gelöscht werden. Ich entferne auch Zeilen mit der Geschwindigkeit NaN.
lines_notime = lines.drop(columns=['time', 'time_delta', 'time_passed'] ) lines_notime.dropna(inplace=True)
Werte runden, für hübschere Tooltips:
lines_notime['distance'] = (lines_notime['distance']/1000).round(decimals=3) lines_notime['km_per_h'] = lines_notime['km_per_h'].round(decimals=1) lines_notime['minutes'] = lines_notime['minutes'].round(decimals=2) lines_notime['slope'] = lines_notime['slope'].round(decimals=2)
Und schließlich können wir die Karte zeichnen, wobei die Geschwindigkeit als Farbe dargestellt wird. Die Style-Funktion weist jedem Liniensegment Farbe und Tooltip zu. Für die Marker (die "Meilensteine" der Splits) verwende ich folium.plugins.BeautifyIcon, dieses Plugin kann Zahlen auf den Marker plotten.
m = folium.Map(location=[location.y, location.x], zoom_start=15, tiles='cartodbpositron')
# Plot the track, color is speed
max_speed = lines['km_per_h'].max()
linear = cm.LinearColormap(['white', 'yellow', 'red'], vmin=0, vmax=max_speed)
route = folium.GeoJson(
lines_notime,
style_function = lambda feature: {
'color': linear(feature['properties']['km_per_h']),
'weight': 3},
tooltip=folium.features.GeoJsonTooltip(
fields=['distance', 'ele', 'km_per_h', 'minutes', 'slope'],
aliases=['Distance', 'Elevation', 'Speed', 'Minutes', 'Slope'])
)
m.add_child(linear)
m.add_child(route)
# Add markers of the splitpoints
for i in range(0,len(splitpoints)):
folium.Marker(
location=[splitpoints.iloc[i].geometry.y, splitpoints.iloc[i].geometry.x],
# popup=str(i),
icon=plugins.BeautifyIcon(icon="arrow-down",
icon_shape="marker",
number=i,
border_color= 'white',
background_color='lightgreen',
border_width=1)
).add_to(m)
m
... und wir bekommen die ganz oben gezeigte Karte.
Zur nächsten Stufe
Es ist schön, einen einzigen GPS-Track auszuwerten. Aber es wäre noch schöner, die Daten aller GPS-Tracks zu analysieren. Ich werde dies im zweiten Teil tun.