Seit ein paar Jahren werden jeden November Social-Media-Seiten wie Twitter mit Karten geflutet: Die 30DayMapChallenge gibt für jeden Tag ein Thema vor und alle sind aufgerufen, entsprechende Karten unter #30DayMapChallenge zu posten. Ich habe diese Challenge in den letzten Jahren begeistert verfolgt und schließlich zum Anlass genommen, mehr über die Möglichkeiten von QGIS usw. zu lernen.
Dieses Jahr habe ich selbst teilgenommen und tatsächlich 30 Karten veröffentlicht (wobei ich die meisten bereits im Oktober erstellt habe). Manche sind richtig gut geworden, andere nur gut genug — und ich habe sehr viel dabei gelernt. Ich habe sogar extra dafür bei Twitter bzw. X einen Account aktiviert — ausgerechnet jetzt, wo viele aus guten Gründen diesem X den Rücken kehren.
Tag 1 | Points

Gaslaternen in Steglitz-Zehlendorf. Die Daten sind vom Geoportal Berlin / Öffentliche Beleuchtung, als WFS in QGIS eingebunden und nach Gaslaternen gefiltert. Dazu passende Glow-Effekte.
Tag 2 | Lines
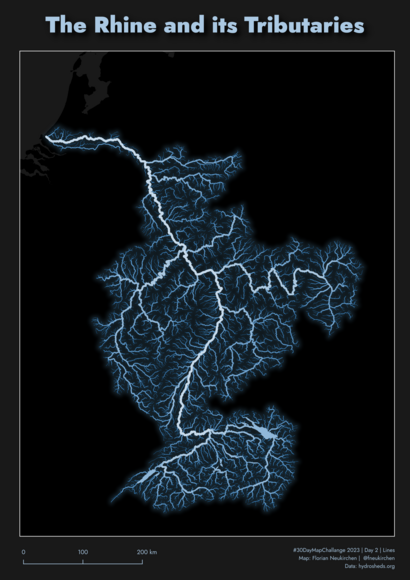
Der Rhein und seine Nebenflüsse, mit Daten von hydrosheds.org. Ich finde diese Karte besonders gelungen, allerdings hatte ich schon eine ähnliche mit der Donau (siehe unten). Es gibt im Netz zahlreiche Tutorials, wie man in QGIS mit den Daten von Hydrosheds z. B. alle Flüsse eines Landes bunt eingefärbt plotten kann. Hier also ein nur ein Flusssystem, in Blau und mit glow. Gefällt mir ganz gut.
Tag 3 | Polygons
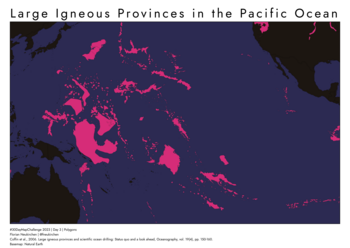
Large Igneous Provinces (LIP) in the Pacific Ocean. Daten von Coffin et al. (2006) und Basemap Natural Earth. Nichts Besonderes…
Tag 4 | A bad map
Ich habe mir hier wirklich Mühe gegeben, eine möglichst schlechte Karte zu machen. Zum Beispiel zwinge ich QGIS mit Expressions, die Labels möglichst schlecht zu platzieren. Das Ergebnis ist gewollt häßlich. Ich habe beim Erstellen dieser Karte durchaus dazu gelernt, aber das Thema finde ich trotzdem nicht so gut.
Tag 5 | Analog Map
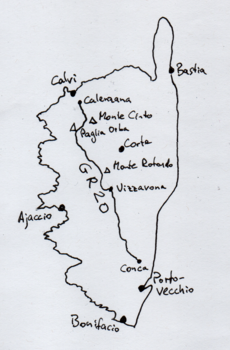
Skizze des GR20 in Korsika. Mit der Hand zu skizzieren ist nicht unbedingt meine Stärke.
Tag 6 | Asia
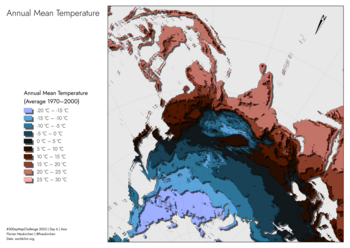
Ich habe versucht, durchschnittliche Temperaturen einmal anders darzustellen: mit Kontur-Polygonen, die einen Schatten werfen. Das Ergebnis ist leider nur mittelmäßig. Die genordete Version sah merkwürdig aus, weil es im Vordergrund mit hohen Temperaturen losgeht und zum Hintergrund quasi abwärts geht. Damit die tiefen Temperaturen im Kartenbild vorne sind, habe ich die Karte umgedreht, was aber auch wieder nicht so gut aussieht. Und allein schon diesen riesigen Kontinent auf eine Karte zu bekommen, ist eine Herausforderung (das ist ESRI’s Asia Lamber Conformal Conic projection).
Tag 7 | Navigation
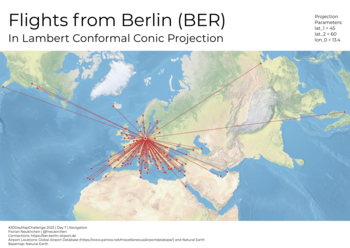
Zu diesem Thema ist mir nicht viel eingefallen. Schließlich habe ich die vom BER startenden Flugrouten kartiert, und zwar in Lamberts winkeltreuer Kegelprojektion mit Berlin im Zentrum. Die Routen entlang der Großkreise werden so zu geraden Linien. Die Daten habe ich mit einem Python-Skript von der Flughafen-Webseite gezogen und in ein CSV umgewandelt (mit beatifulsoup). Es werden einige Miniflughäfen angeflogen, es war zum Teil gar nicht so leicht, die entsprechenden Positionen zu finden. Die Basemap ist Natural Earth „von der Stange“.
Tag 8 | Africa
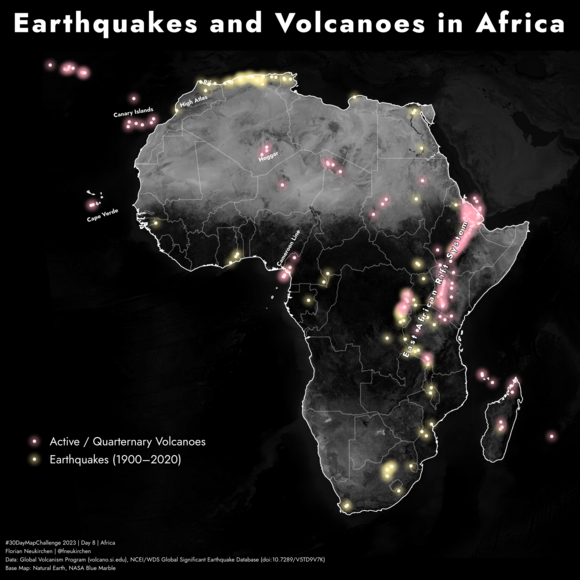
Erdbeben und Vulkane in Afrika. Ein spannendes Thema und es ist eine schöne Karte im „Firefly-Stil“ herausgekommen. Es ist gut zu sehen, wie sich der westliche und der östliche Arm des Ostafrikanischen Grabens unterscheiden. Daten: Global Volcanism Program, NECEI/WDS Global Significant Earthquake Database. Base map: Natural Earth und NASA Blue Marble.
Tag 9 | Hexagons

Diese Karte finde ich sehr gelungen. Sie zeigt in einem hexagonalen Grid die Anzahl der Kitaplätze und die Bevölkerung in Berlin.
Tag 10 | North America
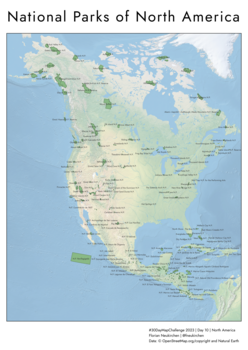
Hier war ich nicht sehr kreativ: eine einfache Karte aller Nationalparks in Nordamerika. Projektion: Albers.
Tag 11 | Retro
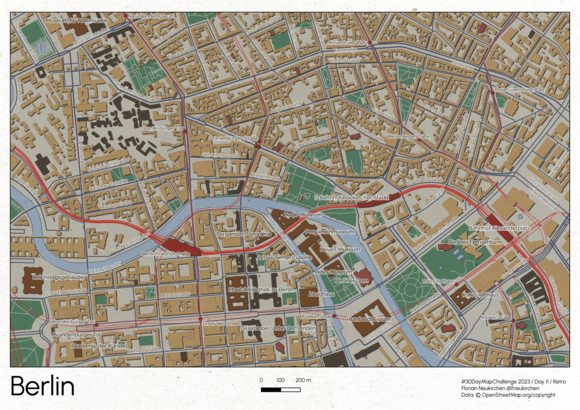
Berlin als Retro-Map. Es hat Spass gemacht, mit den OpenStreetMap-Daten zu spielen und an Farben und Symbolisierung zu schrauben.
Tag 12 | South America
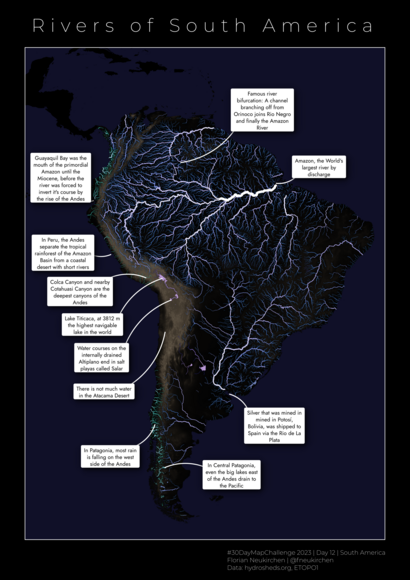
Flüsse in Südamerika und ein paar hydrologische fun facts. Ich mag diese Karte sehr. Daten sind hydrosheds.org und ETOPO1, wie fast alle Karten ist auch diese in QGIS erstellt.
Tag 13 | Choropleth
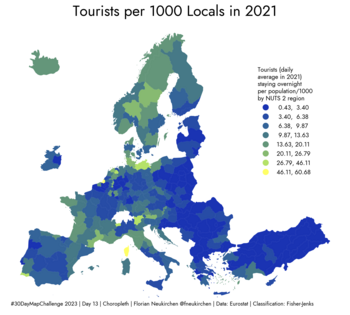
Touristen pro 1000 Einheimische in Europa (2021). Diesmal eine Karte, die ich vollständig in Python (Geopandas) erstellt habe. Daten sind von Eurostat. Zu Recht habe ich die Frage bekommen, warum hier die Türkei dabei ist, aber die Schweiz, UK usw. fehlen. Weiß ist hier „missing data“. Der Grund sind die Daten von Eurostat, wo UK seit dem Brexit nicht dabei ist, EU-Beitrittskandidaten wie die Türkei aber schon. Ich hatte überlegt, die Türkei wegzulassen, fand es aber in diesem Zusammenhang interessant, sie dabei zu lassen.
Tag 14 | Europe

Touristen in Europa: 1 Punkt für alle 50000 Touristen (Übernachtungsgäste) im Jahr 2021. Der gleiche Datensatz wie oben (nach NUTS-2-Region).
Tag 15 | OpenStreetMap
Berlin in Grün… ziemlich einfach, aber ich finde es eigentlich ganz hübsch.
Tag 16 | Oceania
Ich habe diesmal mit diversen Layer-Effekten experimentiert, bin aber vom Ergebnis nicht überzeugt.
Tag 17 | Flow
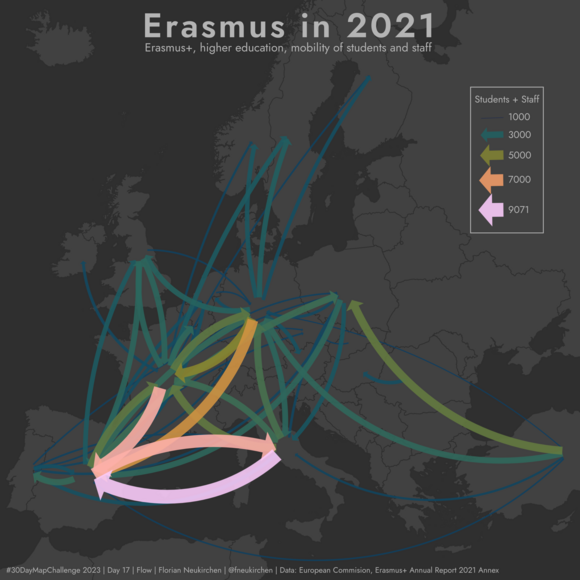
Flow map zur Mobilität im Rahmen von Erasmus im Jahr 2021.
Tag 18 | Atmosphere
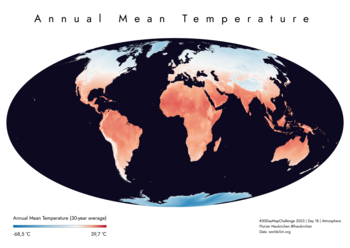
Jährliche Durchschnittstemperatur (von worldclim.org). Ich frage mich, ob die Extremwerte Ausreißer aus der Interpolation sind.
Tag 19 | A 5-minute map
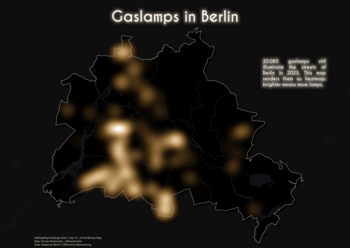
Wieder die Gaslaternen von Tag 1, diesmal als Heatmap.
Tag 20 | Outdoors

Die Cordillera Blanca (Peru) in Gold. Der Metallglanz ist das unerwartete Ergebnis von Experimenten mit Blendingmodes mit verschiedenen aus SRTM erzeugten Hillshade-Layern. Ich finde diese Karte ziemlich cool.
Tag 21 | Raster

Clay Mineral Index (CM) der südwestlichen Ecke von Bolivien. Das ist Band 6 / Band 7 einer Landsat-9-Szene.
Tag 22 | North is not always up
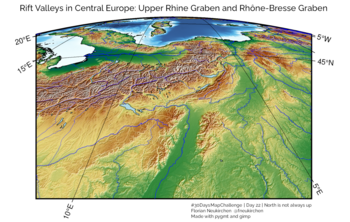
Rift Valley in Central Europe, mit Oberrheingraben und Rhône-Bresse-Graben. Erzeugt in Python mit pygmt mit „general perspective“.
Tag 23 | 3D
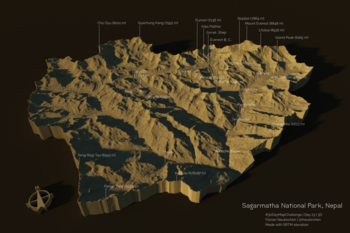
Sagarmatha-Nationalpark in Nepal (mit Mount Everest usw.), gerendert mit Aearialod.
Tag 24 | Black & White
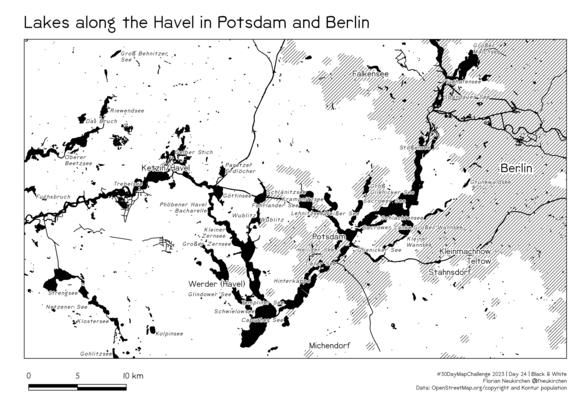
Seen an der Havel in Potsdam und Berlin. Es war eine spannende Herausforderung, nur in Schwarz-Weiß ohne Graustufen zu arbeiten.
Tag 25 | Average Temperature of Antarctica
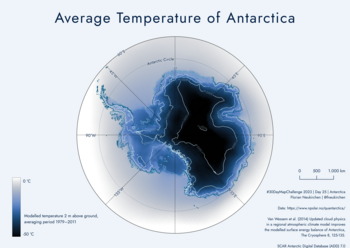
Die Daten sind aus dem Datenpaket quantartica. Besonders gelungen finde ich die 60°S-Linie als Kartenrahmen.
Tag 26 | Minimal
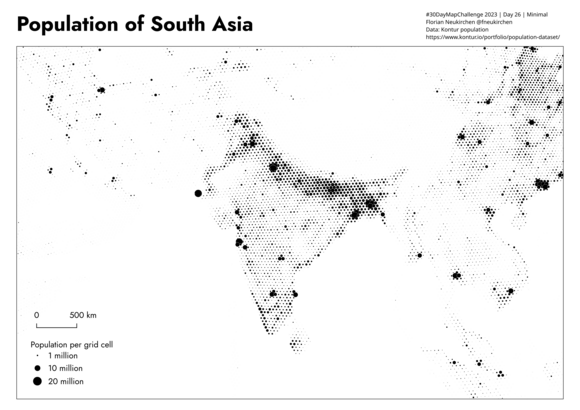
Bevölkerung in Südasien. Der Stil ist von Bertin inspiriert, aber mit einem hexagonalen statt einem quadratischen Grid.
Tag 27 | Dot
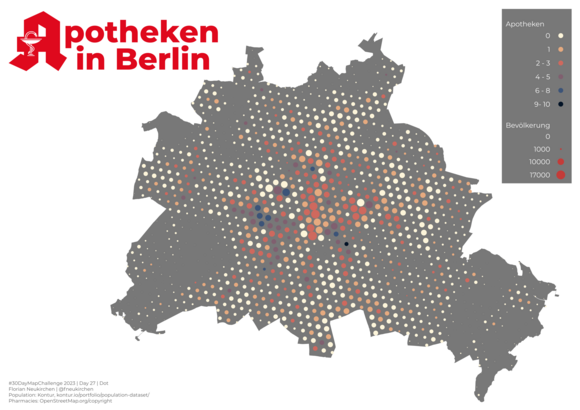
Apotheken in Berlin. Gezeigt sind Anzahl der Apotheken und die Bevölkerung pro Grid-Zelle. Interessant, dass es wohl keine Korrelation gibt.
Tag 28 | Is is a chart or a map?
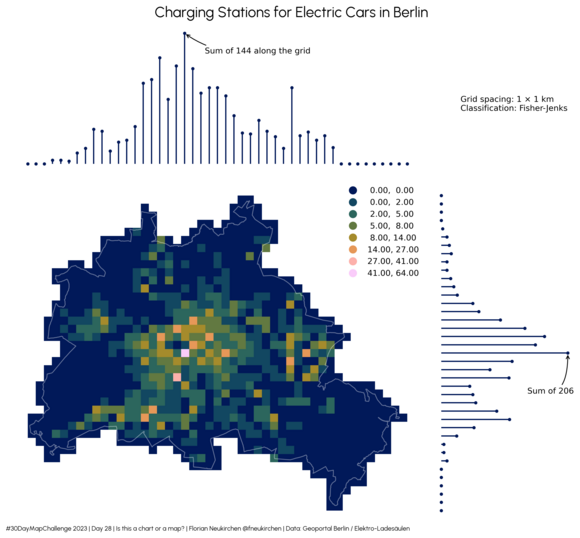
Ladesäulen in Berlin. Inspiriert von einer Karte des USGS wollte ich seitlich Histogramme oder „Lollipop charts“, die die Reihen und Spalten zusammenfassen. Es war nicht leicht, die Subplots so zu erstellen, dass die Achsen zusammenpassen (Python-Code als Jupyter-Notebook).
Tag 29 | Population
Das ist einfach nur ein kleiner Ausschnitt aus dem Global Human Settlement Layer.
Tag 29 | My favorite…
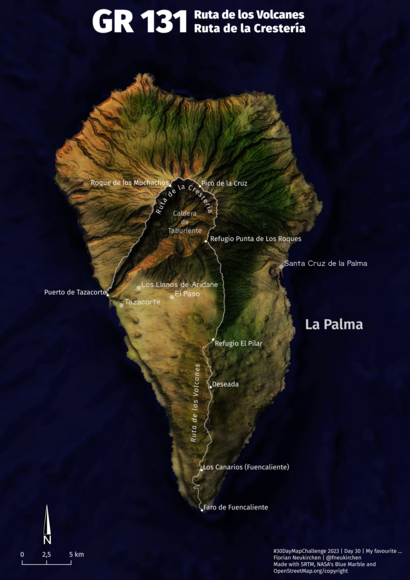
… hike on the Canary Islands, mit dem GR131 (Ruta de los Volcanes / Ruta de la Cresteria) auf La Palma. Und nach meiner Meinung eine meiner gelungensten Karten. Erstellt mit SRTM-Höhendaten, OpenStreetMap und dem Blue Marble der NASA.
MapPromptMonday
Ich habe auch ein paar Karten bei einer anderen Challenge geposted, MapPromptMonday. Hier eine kleine Auswahl.
Straßenbahnlinien in Berlin
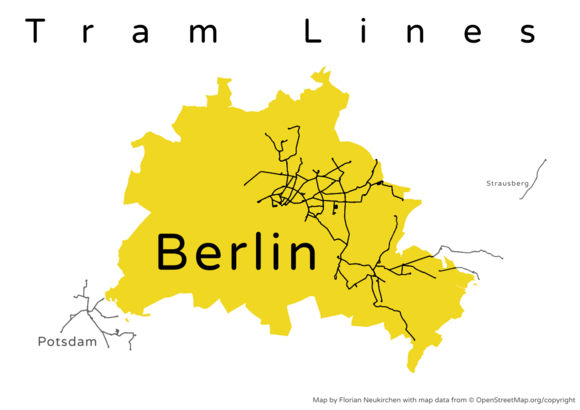
Der Stil ist inspiriert vom BVG-Logo. Es fehlt die neue Linie zur Turmstraße, die ausgerechnet am Wochenende vor der Veröffentlichung meiner Karte eingeweiht wurde.
Donau und ihre Nebenflüsse

Diese Karte war quasi mein Vorläufer zur oben gezeigten Karte des Rheins.
Fledermäuse in Transylvanien
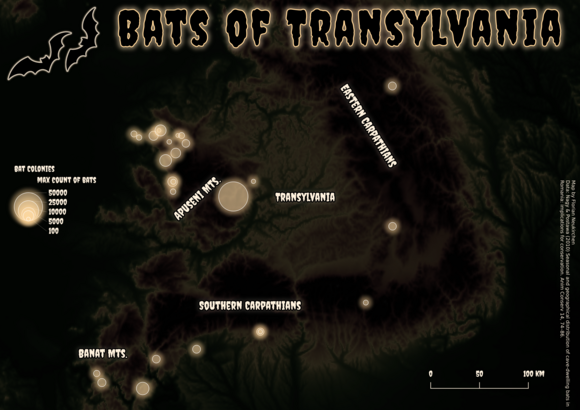
Helloween-Motiv zum Thema „Spooky“.
Health
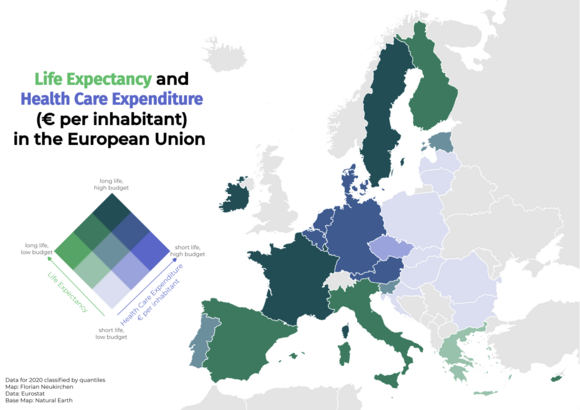
Gibt es einen Zusammenhang zwischen Lebenserwartung und den Pro-Kopf-Ausgaben im Gesundheitssystem? Solche bivariate Karten können in QGIS leicht mit blending modes und zwei Layern erzeugt werden, für die Legende gibt es ein Plugin.
Windgeschwindigkeit in der Antarktis

Die Daten sind auch hier von quantartica. Hier gefallen mir die Farben besonders gut.